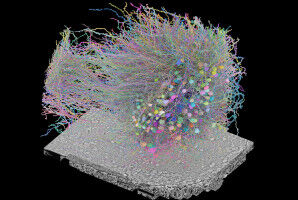
Légende de l’image: Représentation schématique de la prédiction de séquences avec CARBonAra. Le transformeur géométrique échantillonne l’espace de séquence de l’enzyme bêta-lactamase TEM-1 (en gris) complexée à un substrat naturel (en cyan) pour produire de nouvelles enzymes actives et bien repliées. Crédit: Alexandra Banbanaste (EPFL)
La conception de protéines capables de remplir des fonctions spécifiques implique de comprendre et de manipuler leurs séquences et leurs structures. Cette tâche est essentielle au développement de traitements ciblés contre les maladies et à la création d’enzymes pour des applications industrielles.
L’un des grands défis de l’ingénierie des protéines est la conception de protéines de novo, c’est-à-dire à partir de rien, afin d’adapter leurs propriétés à des tâches spécifiques. Cela a d’importantes répercussions pour la biologie, la médecine et la science des matériaux. Par exemple, les protéines modifiées peuvent cibler des maladies avec une grande précision, ce qui offre une alternative efficace aux médicaments traditionnels à base de petites molécules.
De plus, les enzymes sur mesure, qui agissent comme des catalyseurs naturels, peuvent faciliter des réactions rares ou inexistantes dans la nature. Cette capacité est particulièrement utile dans l’industrie pharmaceutique pour la synthèse de molécules médicamenteuses complexes et dans la technologie environnementale pour la décomposition plus efficace des polluants ou des plastiques.
Une équipe de scientifiques sous la houlette de Matteo Dal Peraro de l’EPFL vient de mettre au point CARBonAra (Context-aware Amino acid Recovery from Backbone Atoms and heteroatoms). Reposant sur l’IA, ce modèle unique est capable de prédire les séquences de protéines tout en tenant compte des contraintes imposées par les différents environnements moléculaires. CARBonAra est entraîné sur un ensemble de données d’environ 370 000 sous-unités, avec 100 000 données supplémentaires pour la validation et 70 000 pour le test qui proviennent de la banque de données sur les protéines (PDB) .
CARBonAra s’appuie sur l’architecture du cadre PeSTo (Protein Structure Transformer) , également développé par Lucien Krapp de l’équipe de Matteo Dal Peraro. Il utilise des transformeur géométriques, c’est-à-dire des modèles d’apprentissage profond qui traitent les relations spatiales entre les points, telles que les coordonnées atomiques, pour apprendre et prédire des structures complexes.
CARBonAra peut prédire les séquences d’acides aminés à partir d’un squelette de polymère biologique, à savoir la structure des molécules protéiques. Toutefois, l’une des caractéristiques les plus remarquables de CARBonAra est sa connaissance du contexte, qui est particulièrement visible dans sa façon d’améliorer les taux de récupération de séquence - le pourcentage d’acides aminés corrects prédits à chaque position dans une séquence de protéines par rapport à une séquence de référence connue.
CARBonAra améliore considérablement les taux de récupération quand il inclut des «contextes» moléculaires, comme les interfaces des protéines avec d’autres protéines, des acides nucléiques, des lipides ou des ions. «Cela s’explique par le fait que le modèle est entraîné avec toutes sortes de molécules et s’appuie uniquement sur les coordonnées atomiques, ce qui lui permet de ne pas traiter que les protéines», explique Matteo Dal Peraro. Cette caractéristique renforce le pouvoir prédictif du modèle et son applicabilité dans les systèmes biologiques complexes réels.
Le modèle n’est pas uniquement performant dans les benchmarks synthétiques, mais il a été validé expérimentalement. Les chercheuses et chercheurs ont eu recours à CARBonAra pour concevoir de nouvelles variantes de l’enzyme ß-lactamase TEM-1, qui est impliquée dans le développement de la résistance aux antimicrobiens. Certaines des séquences prédites, qui diffèrent d’environ 50 % de la séquence de type sauvage, ont été repliées correctement et conservent une certaine activité catalytique à des températures élevées, lorsque l’enzyme de type sauvage est déjà inactive.
La flexibilité et la précision de CARBonAra ouvrent de nouvelles voies pour l’ingénierie des protéines. Sa capacité à prendre en compte des environnements moléculaires complexes en fait un outil précieux pour concevoir des protéines aux fonctions spécifiques, améliorant ainsi les futures campagnes de découverte de médicaments. Le succès de CARBonAra en matière d’ingénierie enzymatique démontre également son potentiel pour des applications industrielles et la recherche scientifique.