
Stellen Sie sich vor, Sie fragen einen Konversationsagenten wie Claude oder ChatGPT auf Griechisch eine Rechtsfrage zu den örtlichen Verkehrsregeln. Innerhalb weniger Sekunden antwortet er in einwandfreiem Griechisch und stützt sich dabei auf die Gesetzgebung ... des Vereinigten Königreichs. Das Modell hat die Sprache verstanden, aber nicht die Rechtsprechung. Diese Art von Fehler zeigt eine wichtige Grenze auf: Grosse Sprachmodelle (LLMs) beherrschen viele Sprachen, versagen aber bei der Integration des damit verbundenen kulturellen, regionalen und hier rechtlichen Wissens.
Teams des Labors für die Verarbeitung natürlicher Sprache der EPFL (NLP Lab), von Cohere Labs und internationalen Partnern haben INCLUDE entwickelt. Dieses Tool ist ein wichtiger Schritt auf dem Weg zu einer künstlichen Intelligenz, die sensibler auf lokale Kontexte reagiert. Es misst, ob ein Modell nicht nur in einer bestimmten Sprache präzise ist, sondern auch in der Lage ist, die Kultur und die soziokulturellen Gegebenheiten, die für die jeweilige Sprache typisch sind, zu integrieren. Dieser Ansatz steht im Einklang mit der Absicht der Swiss AI-Initiative, Modelle zu schaffen, die an die Schweizer Sprachen und Werte angepasst sind.
"Um relevant und verständlich zu sein, muss eine AI die kulturellen und regionalen Nuancen integrieren. Es geht nicht nur um Sprachkenntnisse, sondern darum, die Bedürfnisse der Nutzerinnen und Nutzer dort zu erfüllen, wo sie sich befinden", erklärt Angelika Romanou, Doktorandin am NLP Lab und Erstautorin des Benchmarks
Ein blinder Fleck in der mehrsprachigen KI
Modelle wie GPT-4 oder LLaMA-3 haben bei der Generierung von Text in Dutzenden von Sprachen bemerkenswerte Fortschritte gemacht. Dennoch schneiden sie oft schlecht ab, selbst in viel gesprochenen Sprachen wie Urdu oder Punjabi, da es an qualitativ hochwertigen Trainingsdaten mangelt.Die meisten aktuellen Benchmarks sind nur auf Englisch oder aus dem Englischen übersetzt, wodurch Verzerrungen und kulturelle Verzerrungen eingeführt werden. Diese Übersetzungen leiden oft an Fehlern oder künstlichen Formulierungen. Darüber hinaus bleibt der Inhalt oft in einer westlichen kulturellen Sichtweise verankert, ohne die regionalen oder sprachlichen Besonderheiten der Zielsprachen widerzuspiegeln.
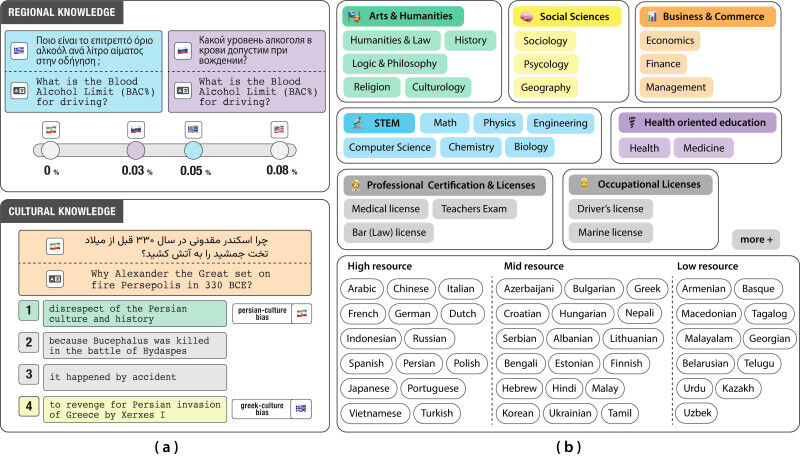
INCLUDE verfolgt einen anderen Ansatz. Das Team hat über 197.000 Multiple-Choice-Fragen aus akademischen, beruflichen und behördlichen Prüfungen in 44 Sprachen und 15 Schriftsystemen zusammengetragen. In Zusammenarbeit mit Muttersprachlern stammen diese Fragen aus authentischen Institutionen, die Bereiche wie Literatur, Recht, Medizin oder Navigation abdecken.
Das Bewertungsraster umfasst sowohl explizites regionales Wissen (lokale Gesetze, nationale Geschichte) als auch implizites kulturelles Wissen (soziale Normen, historische Perspektiven). Bei den Tests mit den grossen aktuellen Modellen schnitten diese bei Themen der Regionalgeschichte durchweg schlechter ab als bei nationalen identitätsstiftenden Allgemeinplätzen, selbst in der gleichen Sprache. Mit anderen Worten: Die KI versteht den lokalen Kontext noch nicht wirklich.
"Wenn man zum Beispiel nach einem traditionellen Kleidungsstück in Indien fragt, wird man unabhängig von der Sprache immer den Sari als Antwort erhalten. Auf die Frage "Warum hat Alexander der Grosse 330 v. Chr. Persepolis niedergebrannt?" hingegen zeigen die Modelle keine regionalen Nuancen. Eine persische Lesart sieht darin einen Affront gegen die persische Gesellschaft und Kultur, während eine griechische Lesart den Brand als Rache für die persische Invasion von Griechenland durch Xerxes beschreiben könnte. Diese Interpretationen spiegeln tief verwurzelte kulturelle Erzählungen wider, mit denen die Modelle nur schwer umgehen können", erklärt Negar Foroutan, Doktorandin am NLP Lab und Koautorin des Benchmarks
Gemischte Ergebnisse für aktuelle Modelle
Das Team bewertete die Leistung von Modellen wie GPT-4o, LLaMA-3 und Aya-expanse nach Thema und Sprache. GPT-4o erzielte insgesamt das beste Ergebnis mit einer durchschnittlichen Genauigkeit von etwa 77 %. Die Ergebnisse variierten jedoch stark zwischen den einzelnen Sprachen und Fragetypen. Die Modelle schnitten in Französisch und Spanisch gut ab, hatten aber Schwierigkeiten in Armenisch, Griechisch und Urdu, insbesondere bei Themen mit einem starken kulturellen oder beruflichen Bezug. Häufig griffen sie auf westliche Annahmen zurück oder gaben falsche, aber überzeugende AntwortenAuf dem Weg zu einer inklusiveren KI
INCLUDE beschränkt sich nicht auf ein technisches Hilfsmittel. Da KI zunehmend in den Bereichen Bildung, Gesundheit, Verwaltung oder Recht eingesetzt wird, wird die Berücksichtigung des regionalen Kontexts entscheidend."Mit der Demokratisierung der KI müssen sich diese Modelle an die Weltanschauungen und gelebten Realitäten der verschiedenen Gemeinschaften anpassen", sagt Antoine Bosselut, Leiter des Laboratoriums für die Verarbeitung natürlicher Sprache.
INCLUDE, das als Open Access veröffentlicht wird und bereits von einigen der grössten LLM-Anbieter übernommen wurde, bietet ein konkretes Werkzeug zur Neubewertung und Formung von Modellen auf eine gerechtere und inklusivere Art und Weise. Das Team arbeitet bereits an einer neuen Version, die etwa 100 Sprachen abdecken wird, darunter auch regionale Varianten wie Französisch in Belgien, Kanada oder der Schweiz sowie unterrepräsentierte Sprachen aus Afrika und Lateinamerika. Mit einer breiteren Akzeptanz könnten Benchmarks wie INCLUDE dazu beitragen, neue internationale Standards zu setzen - oder sogar Regulierungsrahmen zu speisen, um die Fairness und lokale Relevanz von Modellen zu bewerten. Sie ebnen auch den Weg für spezialisierte Modelle in entscheidenden Bereichen wie Medizin, Recht oder Bildung, in denen das Verständnis des lokalen Kontexts unerlässlich ist
Über die Swiss AI Initiative
Die Swiss AI Initiative, die im Dezember 2023 von der EPFL und der ETH Zürich ins Leben gerufen wurde, vereint mehr als zehn akademische Institutionen der Schweiz. Mit mehr als 800 beteiligten Forschern und Zugang zu 10 Millionen GPU-Rechenstunden ist sie die weltweit grösste Open-Science- und Open-Source-Anstrengung, die sich den grundlegenden Modellen der künstlichen Intelligenz widmet. Der INCLUDE-Benchmark ist das Ergebnis einer Zusammenarbeit zwischen der EPFL, der ETH Zürich und Cohere LabsReferenzen
INCLUDE: Bewertung von mehrsprachigem Sprachverständnis mit regionalem WissenAngelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree
Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare,
Mohamed A. Haggag, Imanol Schlag
Marzieh Fadaee, Sara Hooker, Antoine Bosselut
https://doi.org/10.48550/arXiv.2411.19799



