
Immaginate di porre a un agente conversazionale come Claude o ChatGPT una domanda legale in greco sulle norme stradali locali. In pochi secondi, l’agente risponde in un greco impeccabile basandosi sulla... legislazione britannica. Il modello ha capito la lingua, ma non la giurisdizione. Questo tipo di errore rivela un limite importante: i modelli linguistici di grandi dimensioni (LLM) padroneggiano molte lingue, ma non riescono a integrare le conoscenze culturali, regionali e, in questo caso, giuridiche associate.
I team del Laboratorio di elaborazione del linguaggio naturale (NLP Lab) dell’EPFL, di Cohere Labs e di partner internazionali hanno sviluppato INCLUDE, uno strumento che segna un passo importante verso un’intelligenza artificiale più sensibile ai contesti locali. Lo strumento misura se un modello non solo è accurato in una determinata lingua, ma è anche in grado di integrare la cultura e le realtà socioculturali specifiche di quella lingua. Questo approccio è in linea con il desiderio dell’iniziativa svizzera per l’IA di creare modelli adattati alle lingue e ai valori svizzeri.
"Per essere pertinente e comprensibile, l’IA deve incorporare le sfumature culturali e regionali. Non si tratta solo di conoscenze linguistiche, ma di soddisfare le esigenze degli utenti là dove si trovano", spiega Angelika Romanou, dottoranda presso il Laboratorio di PNL e prima autrice del benchmark
Un punto cieco nell’intelligenza artificiale multilingue
Modelli come GPT-4 o LLaMA-3 hanno fatto notevoli progressi nella generazione di testi in decine di lingue. Tuttavia, spesso ottengono risultati mediocri, anche in lingue molto parlate come l’urdu o il punjabi, a causa della mancanza di dati di addestramento di alta qualità.La maggior parte dei benchmark attuali sono solo in inglese o tradotti dall’inglese, il che introduce distorsioni culturali e pregiudizi. Queste traduzioni spesso presentano errori o formulazioni artificiali. Inoltre, il contenuto rimane spesso radicato in una visione culturale occidentale, senza riflettere le specificità regionali o linguistiche delle lingue di destinazione.
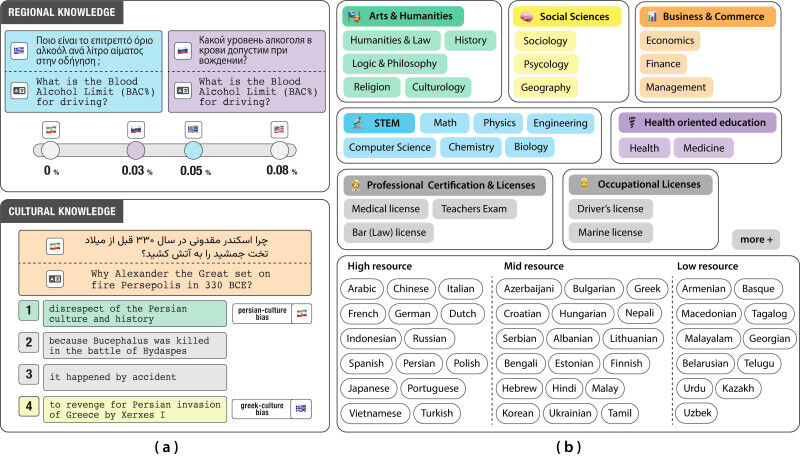
INCLUDE adotta un approccio diverso. Il team ha raccolto oltre 197.000 domande a scelta multipla da esami accademici, professionali e normativi, scritte in 44 lingue e 15 sistemi di scrittura. In collaborazione con persone madrelingua, queste domande provengono da istituzioni autentiche e coprono campi come la letteratura, la legge, la medicina e la navigazione.
La griglia di valutazione comprende sia conoscenze regionali esplicite (leggi locali, storia nazionale) sia conoscenze culturali implicite (norme sociali, prospettive storiche). Quando sono stati testati i principali modelli attuali, hanno sistematicamente ottenuto risultati inferiori su argomenti di storia regionale rispetto alle generalità dell’identità nazionale, anche nella stessa lingua. In altre parole, l’IA non comprende ancora bene il contesto locale.
"Ad esempio, se poniamo una domanda su un indumento tradizionale indossato in India, otterremo sistematicamente come risposta il sari, indipendentemente dalla lingua. D’altra parte, alla domanda: ’Perché Alessandro Magno bruciò Persepoli nel 330 a.C.’, i modelli non mostrano le sfumature regionali. Una lettura persiana lo vede come un affronto alla società e alla cultura persiana, mentre una lettura greca potrebbe descriverlo come una vendetta per l’invasione persiana della Grecia da parte di Serse. Queste interpretazioni riflettono narrazioni culturali profondamente radicate, che i modelli faticano a gestire", spiega Negar Foroutan, dottorando presso il Laboratorio di PNL e coautore del benchmark
Risultati contrastanti per i modelli attuali
Il team ha valutato le prestazioni di modelli come GPT-4o, LLaMA-3 e Aya-expanse per argomento e lingua. GPT-4o ha ottenuto il miglior punteggio complessivo, con un’accuratezza media di circa il 77%. Tuttavia, i risultati variano notevolmente a seconda della lingua e del tipo di domanda. I modelli hanno ottenuto buoni risultati in francese e spagnolo, ma hanno incontrato difficoltà in armeno, greco e urdu, in particolare su argomenti con una forte componente culturale o professionale. Spesso hanno fatto ricorso ad ipotesi occidentali o hanno fornito risposte errate ma convincentiVerso un’IA più inclusiva
INCLUDE non è solo uno strumento tecnico. Poiché l’IA è sempre più utilizzata nei settori dell’istruzione, della sanità, dell’amministrazione e della legge, è fondamentale tenere conto dei contesti regionali."Con la democratizzazione dell’IA, questi modelli devono adattarsi alle visioni del mondo e alle realtà vissute delle diverse comunità", afferma Antoine Bosselut, responsabile del Natural Language Processing Laboratory.
Pubblicato in open access e già adottato da alcuni dei maggiori provider di LLM, INCLUDE offre uno strumento concreto per rivalutare e formare i modelli in modo più equo e inclusivo. Il team sta già lavorando a una nuova versione, che coprirà circa 100 lingue, comprese le varianti regionali come il francese del Belgio, del Canada o della Svizzera, nonché le lingue sottorappresentate dell’Africa e dell’America Latina. Con un’adozione più ampia, i parametri di riferimento come INCLUDE potrebbero contribuire alla definizione di nuovi standard internazionali, o addirittura essere inseriti nei quadri normativi per valutare l’equità e la rilevanza locale dei modelli. Inoltre, aprono la strada a modelli specializzati in settori cruciali come la medicina, la legge o l’istruzione, dove la comprensione del contesto locale è essenziale
L’Iniziativa AI della Svizzera
Lanciata nel dicembre 2023 dall’EPFL e dal Politecnico di Zurigo, la Swiss AI Initiative riunisce più di dieci istituzioni accademiche svizzere. Con oltre 800 ricercatori coinvolti e l’accesso a 10 milioni di ore di GPU Computing, è il più grande sforzo open science e open source al mondo dedicato ai modelli fondamentali di intelligenza artificiale. Il benchmark INCLUDE è il risultato di una collaborazione tra EPFL, ETH di Zurigo e Cohere LabsRiferimenti
INCLUDE: Valutazione della comprensione linguistica multilingue con conoscenze regionaliAngelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree
Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare,
Mohamed A. Haggag, Imanol Schlag
Marzieh Fadaee, Sara Hooker, Antoine Bosselut
https://doi.org/10.48550/arXiv.2411.19799



