Qu’est-ce qu’une IA responsable? Aucune définition consensuelle n’a encore été formulée ni adoptée. L’AI Act de l’Union européenne se limite pour l’instant à une liste de sept principes pour une IA éthique : l’intervention et la supervision humaines; la robustesse et la sécurité techniques; la protection de la vie privée et la gouvernance des données; la transparence; la diversité, la non-discrimination et l’équité; le bien-être sociétal et environnemental et la responsabilité.
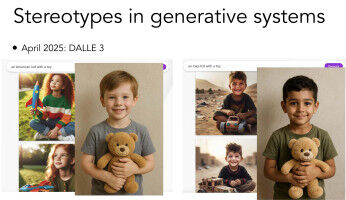
Appliquer ces principes est un défi majeur, notamment lorsqu’il s’agit de biais, qu’ils soient d’ordre idéologique, politique, religieux, sexiste, raciste, ou plus généralement cognitif. «Les biais ne sont pas nouveaux, l’être humain en possède énormément», rappelle Olivier Crochat, directeur du Center for Digital Trust de l’EPFL (C4DT). «L’IA générative devrait permettre d’aborder ce problème tant pour celles et ceux qui développent les algorithmes que pour les utilisatrices ou utilisateurs.» Un résultat biaisé peut servir de données d’entraînement du modèle et par conséquent exacerber ce biais. Les systèmes d’IA générative entraînés sur des données biaisées reproduisent donc les inégalités existantes. Qu’il s’agisse de décisions en matière d’embauche, de crédit hypothécaire ou de reconnaissance faciale, les biais peuvent avoir des conséquences directes sur la vie des individus. Selon la loi européenne, une IA générative véritablement responsable doit donc non seulement être transparente et sécurisée, mais aussi activement conçue pour détecter et corriger ces biais.
Une des craintes est que les algorithmes nourris de fake news, de complotisme, de biais, de propagande ou de censure fassent caisse de résonance, devenant une arme de désinformation massive. «L’algorithme ne va a priori pas faire pire que ce qu’il y a déjà, remarque Olivier Crochat, mais si on ne le corrige pas, il va perpétuer le problème, et s’il est déployé à grande échelle, ceci aura des conséquences néfastes.» Un rapport de l ’Initiative for Media Innovation (IMI), basée à l’EPFL, se montre dans ce sens rassurant. Il a passé au crible les élections de 2024, année durant laquelle près de la moitié de l’humanité a été appelée aux urnes. Les expertes et experts constatent que l’IA n’a effectivement pas bouleversé les résultats des scrutins. Son impact est donc resté limité. Néanmoins, la prolifération des contenus manipulés, amplifiés par des algorithmes, a contribué à une fragmentation des opinions et alimenté un climat de méfiance généralisée.
Le rapport de l’IMI souligne que la manipulation numérique à des fins de propagande n’est pas nouvelle, mais l’IA générative a démultiplié sa capacité. «Nous sommes confrontés à une course entre outils de création et outils de détection», commente Touradj Ebrahimi, professeur spécialisé dans le traitement des signaux multimédia à l’EPFL. Son laboratoire développe des outils de traçabilité et de détection des contenus synthétiques. «Ça reste de l’informatique et si on sait quel est le problème, on peut trouver des solutions pour le résoudre, ajoute le directeur du C4DT. En outre, quand on corrige un biais, il disparaîtra d’emblée pour des millions d’utilisateurs et utilisatrices.»
La question de la responsabilité reste néanmoins centrale. La plupart des outils d’IA générative sont développés et déployés par des entreprises privées, motivées par le profit, qui transfèrent en partie la responsabilité aux utilisateurs. Cela soulève des questions éthiques et juridiques sur la pertinence des valeurs morales dans la gouvernance de l’IA.
L’algorithme ne va a priori pas faire pire que ce qu’il y a déjà, mais si on ne le corrige pas, il va perpétuer le problème, et s’il est déployé à grande échelle, ceci aura des conséquences néfastes.
Olivier Crochat, directeur du Center for Digital Trust (C4DT)
Une responsabilité partagée
«Si l’usage de l’IA relève en dernier ressort de la responsabilité des utilisateurs, des mécanismes de régulation doivent être mis en place pour éviter les abus intentionnels ou accidentels - comme les verrous de sécurité sur les armes ou les bouchons sécurisés sur les médicaments», souligne Sabine Süsstrunk, professeure au Laboratoire d’images et de représentation visuelle de l’EPFL et présidente du Conseil suisse de la science. «Des stratégies éprouvées comme la certification, la réglementation et l’éducation sont nécessaires pour garantir des performances minimales acceptables, clarifier les responsabilités et sensibiliser le public.»Johan Rochel, chargé de cours en droit et éthique de l’IA à l’EPFL et codirecteur d’ethix Lab for Innovation Ethics, explique que la responsabilité ne se distribue pas de façon binaire; elle doit être envisagée comme une répartition tout au long de la chaîne de valeur. Chaque décision de conception logicielle implique des considérations éthiques et des arbitrages, qui doivent être anticipés bien avant que leurs conséquences réelles ne se manifestent.
Le plus n’est pas toujours le mieux
Enfin, un autre paramètre crucial est l’immense quantité de données utilisées pour entraîner les modèles d’IA générative. De nombreuses bases de données sont issues du secteur privé, sans transparence sur leur provenance. Interrogées sur la propriété intellectuelle ou la représentativité des données, les grandes entreprises technologiques écartent souvent les préoccupations éthiques, plaidant que le plus permet de faire du mieux et d’améliorer ainsi la performance de l’IA.«Plus de données, n’est pas nécessairement mieux - ce qui compte, ce sont de meilleures données, insiste Johan Rochel. L’argument de la quantité ne doit pas primer sur les considérations éthiques.» Sabine Süsstrunk ajoute : «Si les données sont protégées par le droit d’auteur, elles doivent être sous licence, achetées ou simplement non utilisées. Malheureusement, l’application des lois sur le droit d’auteur étant contradictoire selon les juridictions, la situation actuelle reste très insatisfaisante.»
Une utilisation transparente et responsable
Comme nombre d’institutions, d’entreprises ou de hautes écoles, l’EPFL s’est dotée de principes d’utilisation des IA génératives. Tout en reconnaissant l’énorme potentiel de ces outils, l’École prône leur utilisation de manière informée, responsable et transparente.
«De manière informée» implique notamment que l’utilisateur ou l’utilisatrice soit consciente des limites et des risques de l’outil et ne lui soumette pas de données personnelles ou confidentielles.
L’utilisation responsable des IA génératives signifie que l’utilisateur doit vérifier l’exactitude, l’objectivité, la qualité ou encore le respect des droits d’auteur des contenus qu’il génère. En dernier recours, il est toujours responsable de ces contenus. L’utilisateur doit aussi être conscient de l’impact énergétique de l’emploi de ces outils.
Enfin, la transparence demande par exemple de mentionner à son ou ses interlocuteurs si un contenu a été généré par l’IA.
L’EPFL publie et met à jour sur son site web ses principes d’utilisation des IA génératives , destinés à ses différents publics.
Comment détecter les criminels sur Signal ou WhatsApp?
Des petits modèles de langage IA pour plus d’efficacité