Laurène Donati and Virginie Uhlmann
Laurène Donati and Virginie Uhlmann
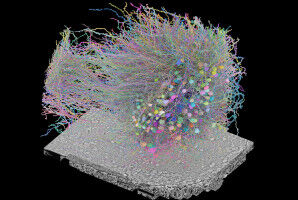
Laurène Donati and Virginie Uhlmann © 2022 Alain Herzog - Deep learning models are becoming increasingly common in bioimage analysis. Yet a lack of standardization and the use of these algorithms by non-experts are potential sources of bias. Scientists from EPFL and the European Bioinformatics Institute (EMBL-EBI) offer practical tips and guidance in a paper recently published in the journal IEEE. Scientists are constantly seeking imaging systems that are faster, more powerful and capable of supporting longer observation times. This is especially true in life sciences, where objects of interest are rarely visible to the naked eye. As technological progress allows us to study life on ever smaller scales of time and space, often at less than nanoscale, researchers are also turning to increasingly powerful artificial intelligence programs to sort through and analyze these vast datasets. Deep learning models - a type of machine learning algorithm that uses multi-layer networks to extract insights from raw input - are growing in popularity among life sciences researchers on account of their speed and precision.
PER LEGGERE QUESTO ARTICOLO, CREA IL TUO ACCOUNT
Ed estendere la vostra lettura, gratuitamente e senza alcun impegno.
I vostri vantaggi
- Accesso a tutti i contenuti
- Ricevere newsmail per le novità e le offerte di lavoro
- Pubblicare annunci